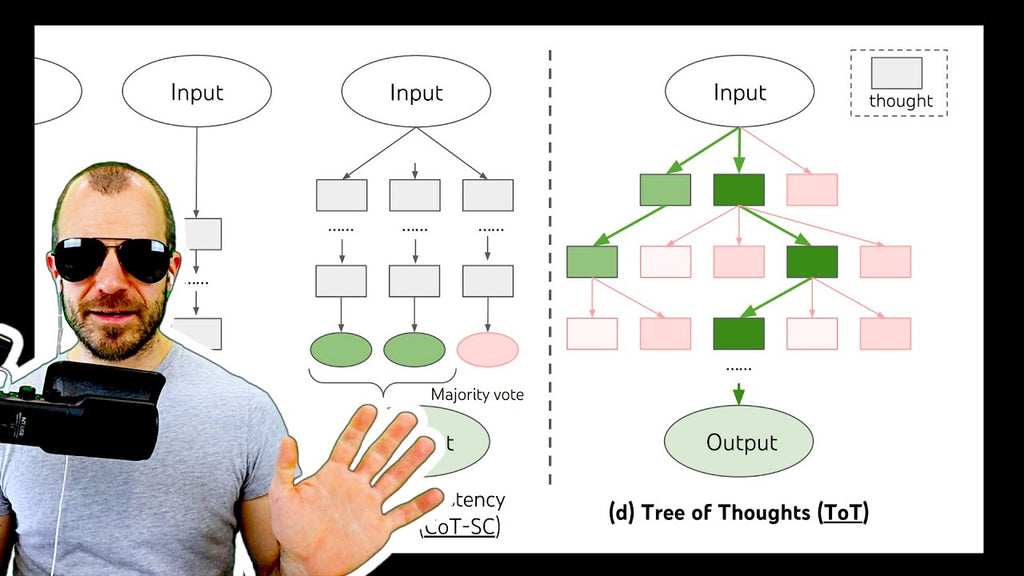
Tree-of-Thought improves prompting of large language models (LLMs) by generalizing the concept of Chain-of-Thought prompting and introduces a tree search across language model thoughts, including state evaluation and backtracking. Experiments on toy tasks show large improvements over both classic and Chain-of-Thought prompting. OUTLINE: 0:00 - Introduction 1:20 - From Chain-of-Thought to Tree-of-Thought 11:10 - Formalizing the algorithm 16:00 - Game of 24 & Creative writing 18:30 - Crosswords 23:30 - Is this a general problem solver? 26:50 - Ablation studies 28:55 - Conclusion Paper: https://arxiv.org/abs/2305.10601
Abstract: Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances language models' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: this https URL.
Authors: Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan